
This talk forms a quiet reflection on how the creation of new digital resources has changed the ways in which we read the past; and an attempt to worry at the substantial impact it is having on the project of the humanities and history more broadly. In the process it asks if the collapse of the boundaries between types of data - inherent in the creation of digital simulcra - is not also challenging us to rethink the 'humanities' and all the sub-disciplines of which it is comprised. I really just want to ask, if new readings have resulted in new thinking? And if so, whether that new thinking is of the sort we actually want?
As Lewis Mumford suggested some fifty years ago, most of the time:
‘… minds unduly fascinated by computers carefully confine themselves to asking only the kind of question that computers can answer...’
Lewis Mumford, “The Sky Line "Mother Jacobs Home Remedies",” The New Yorker, December 1, 1962, p. 148.
But, it seems to me that we can do better than that, but that in the process we need to think a bit harder than we have about the nature of the Digital History project.
Perhaps the obvious starting point is with the concept of the distant reading of text, and that wonderful sense that millions of words can be consumed in a single gulp. Emerging largely from literary studies, and in the work of Franco Moretti and Stephen Ramsay, the sense that text – or at least literature – can be usefully re-read with the tools of the digital humanities has been regularly re-stated with the all the hyperbole for which the Digital Humanities is so well known. And, within reason, that hyperbole is justified.
My favourite example of this approach is Ben Schmidt’s analysis of the dialogue in Mad Men, in which he compares the language deployed by the scriptwriters against the corpus of text published in that particular year drawn from Google books. In the process he illustrates that early episodes over-state the ‘performative’ character of the language, particularly in relation to masculinity – that the scriptwriters chose to depict male characters talking about the outside world and objects, more frequently than did the writers of the early fifties. And that in the later episodes of the series, they depict male characters over-using words associated with interiority, emotions and personal perceptions. What I like about this is that it forms one of the first times I have been really surprised by ‘distant reading’. I just had not clocked that the series was developing a theme along these lines – that it embedded a story of the evolution of masculinity from a performative to an interiorised variety. But once Schmidt used a form of distant reading to expose the transition it felt right, obvious and insightful. In Schmidt’s words: ‘the show's departures from the past… let us see just how much everything has changed, even more than its successes.’… at mimicking past language. The same could be done with the works of George Elliot or Tolstoy (who both wrote essentially ‘historical’ novels), and with them too, I look forward to being surprised. In other words, the existence of something like Google Books and the Ngram viewer - which Schmidt's work depends upon - actually can change the character of how we ‘read’ a sentence, a word, a phrase, a genre – by giving a norm against which to compare it. Is it a ‘normal’ word, for the date? or more challenging, for the genre? for the place of publication? for the word's place in the long string of words that make up an article or a book?

But having lauded this example, I think we also have to admit that in most stabs at distant reading seems to tell us what we already know.

There was an industrial revolution involving iron. There was a war in the 1860s and so on.
What surprises me most, is that I am not more surprised.
In part, I suspect the banal character of most ngrams and network analyses is a reflection of the extent to which books, indexes, and text, have themselves been a very effective technology for thinking about words. And that as long as we are using digital technology to re-examine text, we are going to have a hard time competing with two hundred years of library science, and humanist enquiry. Our questions are still largely determined by the technology of books and library science, so it is little wonder that our answers look like those found through an older techonology.

But, the further we move away from either the narrow literary cannon; and more importantly the code that is text, to include other types of readings of other types of data - sound, objects, spaces - I hope the more unusual and surprising our readings – both close and distant - might become. And it is not just text and objects, but also cultures. The current collection of digital material that forms the basis for most of our research is composed of the maudlin leavings of rich dead white men (and some rich dead white women). Until we get around to including the non-cannonical, the non-Western, the non-textual and the non-elite, we are unlikely to be very surprised.
For myself, I am wondering how we might relate non-text to text more effectively; and how we might combine - for historical purposes - close and distant reading into a single intellectual practise; how we might identify new objects of study, rather than applying new methodologies to the same old bunch of stuff. And just by way of a personal starting point, I want to introduce Sarah Durrant. She is not important. Her experience does not change anything, but she does provide a slightly different starting point from all the rich dead white men. And for me, she represents a different way of thinking through how to ask questions of computers, without simply asking questions we know computers can answer.
Sarah claimed to have found two bank notes on the floor of the coffee house she ran in the London Road, on the Whitsun Tuesday, 1871; at which point she pocketed them. In fact they had been lifted from the briefcase of Sydney Tomlin, in the entrance way of the Birkbeck Bank, Chancery Lane, a few days earlier.

We know what Sarah looked like. This image is part of the record of her imprisonment at Wandsworth Gaol for two years at hard labour, and is readily available through the website of the UK's National Archives. We have her image, her details, her widowed status, the existence of two moles - one on her nose and the other on her chin. We have her scared and resentful eyes staring at us from a mug shot. I don't have the skill to interpret this representation in the context of the history of portraiture, or the history of photography - but it creates a powerful if under-theorised alternative starting point from which to read text - and has the great advantage of not being ‘text’; or at least not being words.
But, we also have the words recorded in her trial.

And because we have marked up this material to within an inch of their life in XML to create layer upon layer of associated data, we also have something more.

In other words, for Sarah, we can locate her words, and her image, her imprisonment and experience, both in ‘text’ and in the leavings of the administration of a trial, as marked up in the XML. And because we have studiously been giving this stuff away for a decade, there is a further ‘reading’ that is possible, via an additional layer of XML provided by Magnus Huber and his team at the University of Giessen. He has marked up all the text that purports to encompass a ‘speech act’. And so we also have a further ‘reading’ of Sarah as a speaker, and not just any speaker, but a working class female speaker in her 60s.

And of course, this allows us to compare what she says, to other women of the same age and class, using the same words; with a bit of context for the usage.
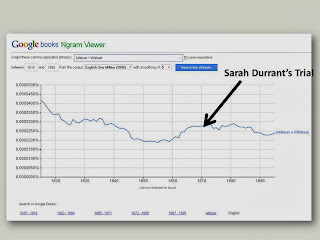
So, we already have a few ‘readings’, including text, bureaucratic process, and purported speech.
From all of which we know that Sarah, moles and all, was convicted of receiving; and that she had been turned in by a Mrs Seyfert - a drunk, who Durrant had refused a hand-out. And we know that she thought of her days in relation to the Anglican calendar, which by 1871, was becoming less and less usual – and reflects the language of her childhood.

And, of course, we have an image of the original page on which that report was published – a ghost of the material leavings of an administrative process.

And just in case, we can also read the newspaper report of the same trial.
So far, so much text, with a couple of layers of XML, and the odd image. But we also know who was in Wandsworth Gaol with her on the census day in 1871.

And we know where Durrant had been living when the crime took place – in Southwark, at No 1 London Road.

We know that she was a little uncertain about her age, and we know who lived up one flight of stairs, and down another. Almost randomly, we can now know an awful lot about most nineteenth century Londoners, allowing us to undertake a new kind of 'close reading'.
From which it is a small step to The Booth Archive site posted by the London School of Economics, which in turn lets us know a bit more about the street and its residents.

‘a busy shopping street', with the social class of the residents declining sharply to the West - coded Red for lower middle class.

But we can still do a bit better than this. We can also do what linguists and literary scholars are doing to their own objects of study - we can take apart the trial, for instance, as a form of generic text using facilities such as Voyant Tools. Turning a ‘historical reading’ in to a linguistic one:

And, if the OCR of the Times Digital Archive was sufficiently good (which it isn’t) - we could have compared the trial account, with the newspaper account as a measurable body of text.
And as with Magnus Huber’s Corpus mark-up, using that linguistic reading of an individual trial as a whole, in relation to Google Books, we could both identify the words that make this trial distinctive, and start the process of contextualising them. We could worry, for instance, at the fact that the trial includes a very early appearance of a 'Detective' giving evidence, and suggesting that Sarah’s experience was unusual and new - providing a different reading again:

In other words, our ability to do a bit of close reading - of lives, of people, of happenstance, and text, with a bit of context thrown in, has become much deeper than it was fifteen years ago.
But we can go further still. We could contextualise Sarah's experience among that of some 240,000 defendants like her, brought to trial over 239 years at the Old Bailey, and reported in 197,475 different accounts. We can visualise these trials by length, and code them for murder and manslaughter, or we could just as easily do it by verdict, or gender, punishment, or crime location. The following material is the outcome of a joint research project with William Turkel at the University of Western Ontario.

Sarah Durrant is here:

And in the process we can locate her experience in relation to the rise of ‘plea bargaining’ and the evolution of a new bureaucracy of judgement and punishment, as evidenced here:

Sarah’s case stood in the middle of a period during which, for the first time, large numbers of trials were being determined in negotiation with the police and the legal profession – all back-rooms and truncheons – resulting in a whole new slew of trials that were reported in just a few words. Read in conjunction with the unusual appearance of a ‘detective’ in the text, and her own use of the language of her youth, the character of her experience becomes subtly different, subtly shaded.
To put this differently, one of the most interesting things we can know about Sarah, is that she was confronted by a new system of policing, and a new system of trial and punishment, which her own language somehow suggests she would have found strange and hard to navigate. We also know that she was desperate to enter a plea bargain. "I know I have done wrong; but don't take me ... [to the station], or I shall get ten years"— pleading to be let go, in exchange for the two bank notes.
And in the end, it was the court's choice to refuse Durrant's plea for a bargain:
"THE COURT would not withdraw the case from the Jury, and stated, the case depended entirely upon the value of the things stolen. GUILTY of receiving— Two Years' Imprisonment."
In other words, Sarah’s case exemplifies the implementation of a new system of justice in which the state – the police and the court – took to themselves a new power to impose its will on the individual. And, it also exemplifies the difficulty that many people – both the poor and the old – must have had in knowing how to navigate that knew system.
But it also places her in a new system designed to ensure an ever more certain and rising conviction rate. And of course, we can see Sarah’s place in that story as well:

Even without the plea bargain, Sarah’s conviction was almost certain – coming as it did in a period during which a higher proportion of defendants were found guilty than at almost any other time before or since. Modern British felony conviction rates are in the mid-70 percent range.
Or alternatively, we can go back to the trial text and use it to locate similar trials – ‘More like this’ – using a TF-IDF – text frequency/inverse document frequency methodology, to find the ten or hundred most similar trials.

In fact these seem to be noteworthy mainly for the appearance of bank-notes and female defendants, and the average length of the trials – none, for instance, can be found among the shorter plea bargains trials at the bottom of the graph, and instead are scattered across the upper reaches, and are restricted to the second half of the nineteenth century - sitting amongst the trials involving the theft of 'bank notes'; and theft more generally, which were themselves, much more likely than crimes of violence, to result in a guilty verdict. At a time when the theft resulted in a conviction rates of between 78% and 82%; killings had a conviction rate of between 41% and 57%.

In other words, applying TF-IDF methodologies provides a kind of bridge between the close and distant readings of Sarah's trial.
And of course, while I don’t do topic modelling, you could equally apply this technique to the text, by simply thinking of the trials as ‘topics’; and I suspect you would find similar results.
But we can read it in other ways as well. We can measure, for instance, whether the trial text has a consistent relationship with the trial outcome - did the evidence naturally lead to the verdict? This work is the result of a collaboration between myself and Simon DeDeo and Sara Klingenstein at the Santa Fe Institute (see Dedeo, et al, 'Bootstrap Methods for the Empirical Study of Decision-Making and Information Flows in Social Systems', for a reflection of one aspect of this work). And in fact, trial texts by the 1870s did not have a consistent relationship to verdicts - probably reflecting again the extent to which legal negotiations were increasingly being entered in to outside the courtroom itself, in police cells, and judge’s chambers - meaning the trials themselves become less useful as a description of the bureaucratic process:

Or, coming out of the same collaboration, we can look to alternative measures of the semantic content of each trial - in this instance, a measure of the changing location of violent language. This analysis is based on a form of ‘explicit semantics’, using the categories of Roget’s thesaurus to group words by meaning. Durrant's trial was significantly, but typically, for 1871, unencumbered with the language of violence. Whereas, seventy years earlier, it would as equally, be likely to contain descriptions of violence – even though it was a trial for that most white collar of crimes, receiving.

In other words, the creation of new tools and bodies of data, have allowed us to 'read' this simple text and the underlying bureaucratic event that brought it into existence, and arguably some of the social experience of a single individual, in a series of new ways. We can do ‘distant reading’, and see this trial account in the context of 127 million words - or indeed the billions of words in Google Books; and we can do a close reading, seeing Sarah herself in her geographical and social context.
In this instance, each of these readings, seems to reinforce a larger story about the evolution of the court, of a life, of a place - a story about the rise of the bureaucracy of the modern state, and of criminal justice. But it was largely by starting from a picture, a face, a stair of fear, that the story emerged.
But the point is wider than this. Reading text – close, distant, computationally, or immersively - is the vanilla sex of the digital humanities and digital history. It is all about what might be characterised as the 'textual humanities'. And for all the fact that we have mapped and photographed her, Sarah remains most fully represented in the text of her trial. But, if you want something with a bit more flavour we need to move beyond what was deliberately coded to text – or photographs – and be more adventurous in what we are reading.
In performance art, in geography and archaeology, in music and linguistics, new forms of reading are emerging with each passing year that seem to significantly challenge our sense of the ‘object of study’. In part, this is simply a reflection of the fact that all our senses and measures are suddenly open to new forms of analysis and representation - when everything is digital, everything can be read in a new way.
Consider for a moment:

This is the ‘LIVE’ project from the Royal Veterinary College in London, and their ‘Haptic Interface’. In this instance they have developed a full scale ‘haptic’ representation of a cow in labour, facing a difficult birth, which allows students to physically engage and experience the process of manipulating a calf in situ. I haven’t had a chance to try this, but I am told that it is a mind altering experience. But for the purpose of understanding Sarah’s world, it also presents the possibility of holding the banknotes, of diving surreptitiously into the briefcase, of feeling the damp wall of her cell, and the worn wooden rail of the bar at the court. It suggests that reading can be different; and should include the haptic - the feel and heft of a thing in your hand. This is being coded for millions of objects through 3d scanning; but we do not yet have an effective way of incorporating that 3d text in to how we read the past.
The same could be said of the aural - that weird world of sound on which we continually impose the order of language, music and meaning; but which is in fact a stream of sensations filtered through place and culture.

Projects like the Virtual St Paul's Cross, which allows you to ‘hear’ John Donne’s sermons from the 1620s, from different vantage points around the square, changes how we imagine them, and moves from ‘text’ to something much more complex, and powerful. And begins to navigate that normally unbridgeable space between text and the material world.
For Sarah, my part of a larger project to digitise andlink the records of nineteenth-century criminal transportation and imprisonment, is to create a soundscape of the courtroom where Sarah was condemned; and to re-create the aural experience of the defendant - what it felt like to speak to power, and what it felt like to have power spoken at you from the bench. And in turn, to use that knowledge, to assess who was more effective in their dealings with the court, and whether, having a bit of shirt to you, for instance, effected your experience of transportation or imprisonment.
All of which is to state the obvious. There are lots of new readings that change how we connect with historical evidence – whether that is text, or something more interesting. In creating new digital forms of inherited culture - the stuff of the dead - we naturally innovate, and naturally enough, discover ever changing readings.
And in the process it feels that we are slowly creating an environment like Katy Börner's notion of a Macroscope - that set of tools, and digital architecture, that allows us to see small and large, at one and the same time; to see Sarah Durrant's moles, while looking at 127 million words of text.

But, before I descend in to that somewhat irritating, Digital Humanities cliché where every development is greeted as both revolutionary, and life enhancing - before I become a fully paid up techno-utopian, I did want to suggest that perhaps all of these developments still leave us with the problem I started with - that the technology is defining the questions we ask. And it is precisely here, that I start to worry at the second half of my title: the 'conundrums of positivism'.
About four years ago - in 2009 or so, I was confronted by something I had not expected. At that time, Bob Shoemaker and I had been working on digitising trial records and eighteenth-century manuscripts for the Old Bailey and London Lives projects for about ten years. In the Old Bailey we had some 127 million words of accurately transcribed text and in the London Lives site, we had 240,000 pages of manuscript materials reflecting the administration of poverty and crime in eighteenth-century London - all transcribed and marked up for re-use and abuse by a wider community of scholars. It all felt pretty cool to me.
But for all the joys of discovery and search digitisation made possible, and the joys of representing the underlying data statistically; none of it had really changed my basic approach to historical scholarship. I kept on doing what I had always done - which basically involved reading a bunch of stuff, tracing a bunch of people and decisions across the archives of eighteenth-century London, and using the resulting knowledge to essentially commentate on the wider historiography of the place and period. My work was made easier, the publications more fully evidenced, and new links and associations were created, that did substantially change how one might look at communities and agency. But, intellectually, digitisation, the digital humanities, did not feel different to me, than had the history writing of twenty years before – to that point, I found myself remarkable un-surprised. But then something happened.
About that time, Google Earth was beginning to impact on geography. With its light, browser based approach to GIS, it had allowed a number of people to create some powerful new sites. Just in my own small intellectual backyard, people like Richard Rogers and a team of collaborators out the National Library of Scotland, were building sites that allowed historical maps to be manipulated, and populated with statistical evidence, online, and in a relatively intuitive Google maps interface. And this was complemented by others, such as the New York Public Library warping site.

It was an obvious thing to want to do something similar for London. And it was a desire to recreate something like this, that led to the Locating London's Past, a screenshot of which I have used already a couple of times. The site used a warped and rectified version of John Rocque's 1746 map of London, in association with the first 'accurate' OS map of the same area, all tied up in a Google Maps container, to map 32,000 place names, and 40,000 trials, and a bunch of other stuff.

But this was where I had my comeuppance. Because in making this project happen, I found myself working with Peter Rauxloh at the Museum of London Archaeological Service, and several of his colleagues - all archaeologists of one sort or another. And from the moment we sat down at the first project meeting, I realised that I was confronted with something that fundamentally challenged my every assumption about history and the past. What shocked me was that they actually believed it.
Up till then it had been a foundational belief of my own, that while we can know and touch the leavings of the dead, the relationship between a past 'reality' and our understanding of it was essentially unknowable - that while we used the internal consistency of the archive to test our conclusions, and in order to build ever more compelling descriptions and explanations of change - actually, we were studying something that was internally consistent, but detached from a knowable reality. In most cases, we were studying 'text', and text alone - with its at least ambiguous relationship to either the mind of the author (whatever that is), and certainly an ambiguous relationship to the world the author inhabited.
Confronted by people happy to define a point on the earth's surface as three simple numbers, and to claim that it was always so, was a shock. This is not to say that the archaeologists were being naïve, far from it, but that having been trained up as a text historian - essentially a textual critic - in those meetings I came face to face with the existence of a different kind of knowing. And, of course, this was also about the time that 'culturomics' was gaining extensive international attention; with its claim to be able to 'read' history from large scale textual change, and to create a 'scientific' analysis of the past. Lieberman Aiden and Michel claim that the process of digitisation, has suddenly made the past available for what they themselves describe as 'scientific purposes
In some respects, we have been here before. In the demographic and cliometric history so popular through the 1970s and 80s, extensive data sets were used to explore past societies and human behaviour. The aspirations of that generation of historians were just as ambitious as are those of the creators of culturomics. But, demography and cliometrics started from a detailed model of how societies work, and sought to test that model against the evidence; revising it in light of each new sample and equation.
The difference with most 'big data' approaches and culturomics is that there is no pretence to a model. Instead, their practitioners seek to discover patterns in the entrails of human leavings hoping to find the inherent meanings encoded there. What I think the scientific community - and quite frankly most historians - finds so compelling is that like quantitative biology and DNA analysis, big data is using one of the controlling metaphors of 20th-century science, 'code breaking' and applying it to a field that has hitherto resisted the siren call of analytical positivism.
Since the 1940s the notion that 'codes' can be cracked to reveal a new understanding of 'nature' has formed the main narrative of science. With the re-description of DNA as just one more code in the 1950s, wartime computer science became a peacetime biological frontier. In other words, what both textual ‘big data’, and the spatial turn, bring to the table is a different set of understandings about the relationship between the historical 'object of study', and a knowable human history; all expressed in the metaphor of the moment - code.
We can all agree that text and objects and landscape form the stuff of historical scholarship, and I suspect that none of us would want to put an exclusionary boundary around that body of stuff. But simply because the results of big data analysis are represented in the grammar of maths (and in 'shock and awe' graphics); or in hyper-precise locations referenced against the modern earth's surface, there is an assumption about the character of the 'truth' the data gives us access to. One need look no further than the use of 'power law' distributions - and the belief that their emergence from raw data reflects an inherently 'natural' phenomenon - to begin to understand how fundamentally at odds traditional forms of historical analysis - certainly in the humanities - is from the emerging 'scientific' histories associated with 'big data'.
But, it is not really my purpose to criticise either the Culturomics team, or archaeologists and geographers (who are themselves engaged in their own form of auto-critique). Rather I just want to emphasise that in choosing to move towards a 'big data' approach - new ways of reading the past - and in adopting the forms of representation and analysis that come with big data, all of us are naturally being pushed subtly towards a kind of social science, and a kind of positivism, which has been profoundly out of favour for at least the last thirty years.
In other words, there seems to me to be a real tension between the desire on the one hand to include the 'reading' of a whole new variety of data in to the process of writing history; and, on the other, the extent to which each attempt to do so, tends to bring to the fore a form of understanding that is at odds with much of the scholarship of the last forty years. We are in danger of giving ourselves over to what sociologists refer to as 'problem closure' - the tendency to reinvent the problem to pose questions that available tools and data allow us to answer - or in Lewis Mumfords words, ask questions we know that computers can answer.
It feels to me as if our practise as humanists and historians is being driven by the technology, rather than being served by it. And really, the issue is that while we have a strong theoretical base from which to critique the close reading of text - we know how complex text is - we do not have the same theoretical framework within which to understand how to read a space, a place, an object, or the inside of a pregnant cow - all suddenly mediated and brought together by code - or to critique the reading of text at a distance. And as importantly, even if there are bodies of theory directed individually at each of these different forms of stuff (and there are); we certainly do not have a theoretical framework of the sort that would allow us to relate our analysis of the haptic, with the textual, the aural and the geographical. Having built our theory on the sands of textuality, we need to re-invent it for the seas of data.
But to come to some kind of conclusion: history is not the past, it is a genre constructed by us from practises first delineated during the enlightenment. Its forms of textual criticism, its claims to authority, its literary conventions, the professional edifice which sifts and judges the product; its very nature and relationship with a reading and thinking public; its engagement with memory and policy, literature and imagination, are ours to make and remake as seems most useful.
For myself, I will read anew, and use all the tools of big data, of ngrams and power laws; and I will publish the results with graphs, tables and GIS; but I refuse to forget that my object of study, my objective, is an emotional, imaginative and empathetic engagement with Sarah Durrant, and all the people like her.

{kind=link}